

Highlights
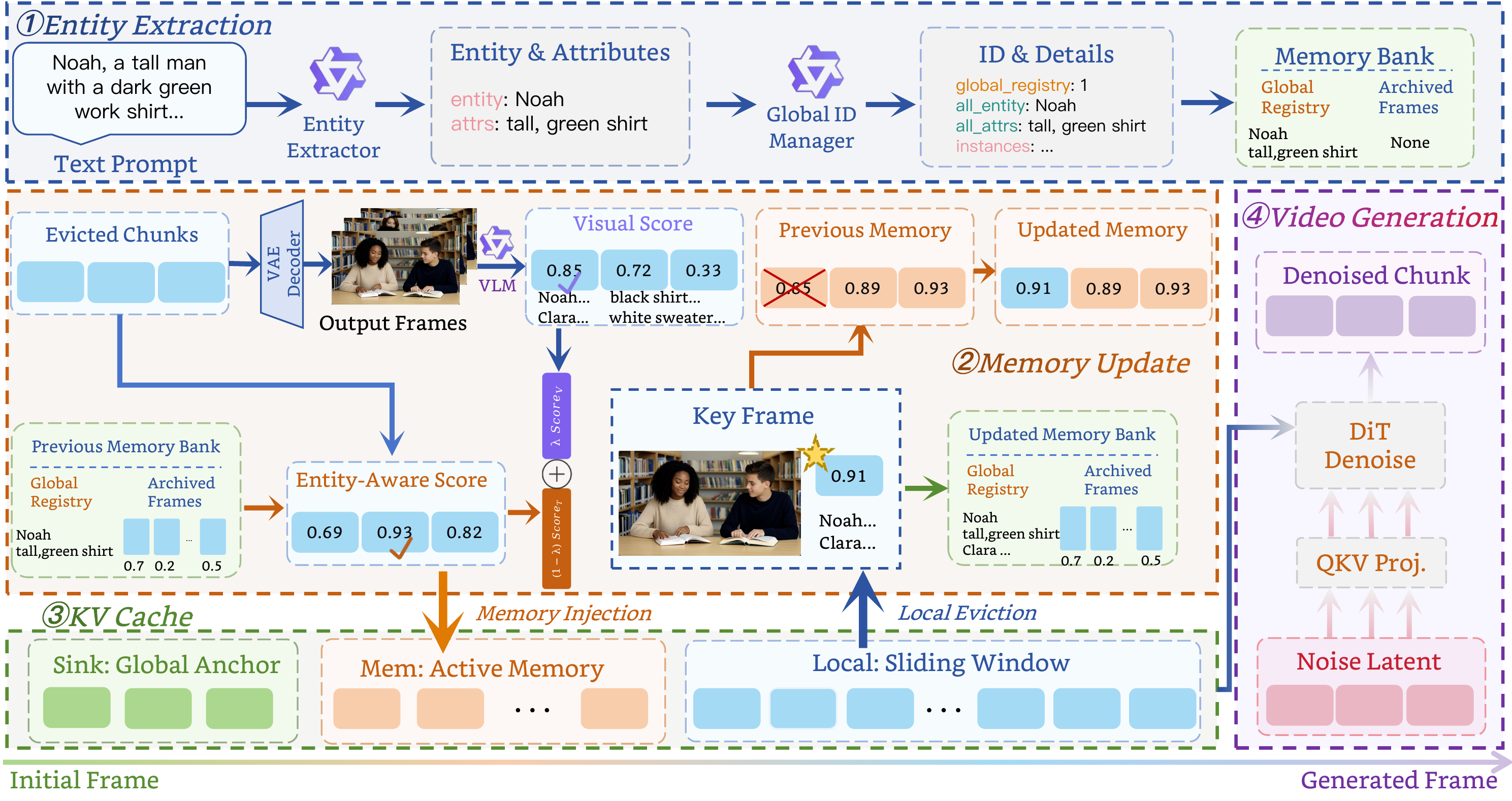
(1) We introduce IAMFlow , a training-free identity-aware memory framework that explicitly organizes historical information around persistent entities and attributes, enabling reliable identity preservation across evolving prompt transitions.
(2) We design a systematic inference acceleration pipeline , to make the framework computationally practical, combining asynchronous visual verification, adaptive prompt transition, and model quantization to preserve long-term consistency without sacrificing generation speed.
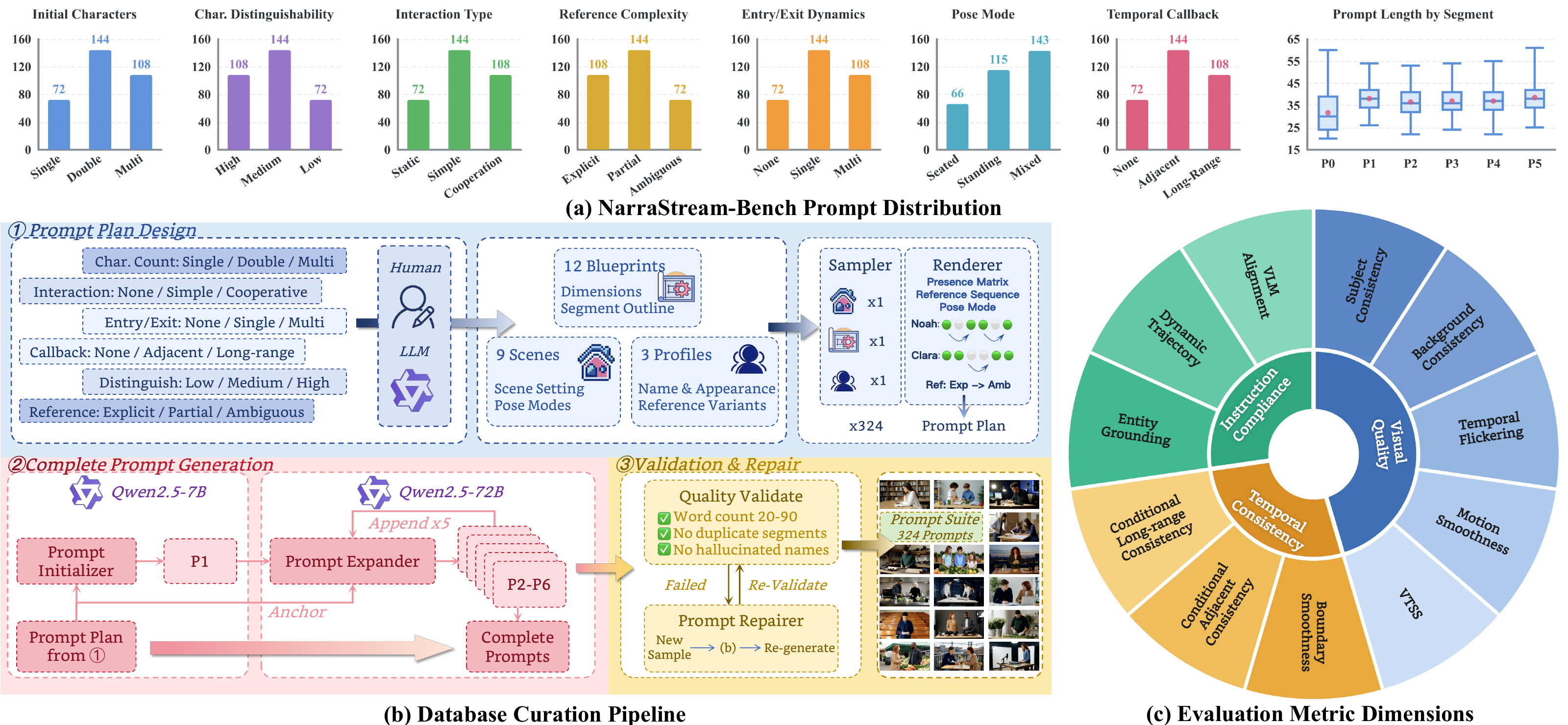
(3) We introduce NarraStream-Bench , a modern benchmark suite for assessing long-term consistency in narrative streaming video generation. Extensive experiments and ablation studies demonstrate that IAMFlow achieves superior performance across various metrics while enabling more efficient inference.
Demo Videos
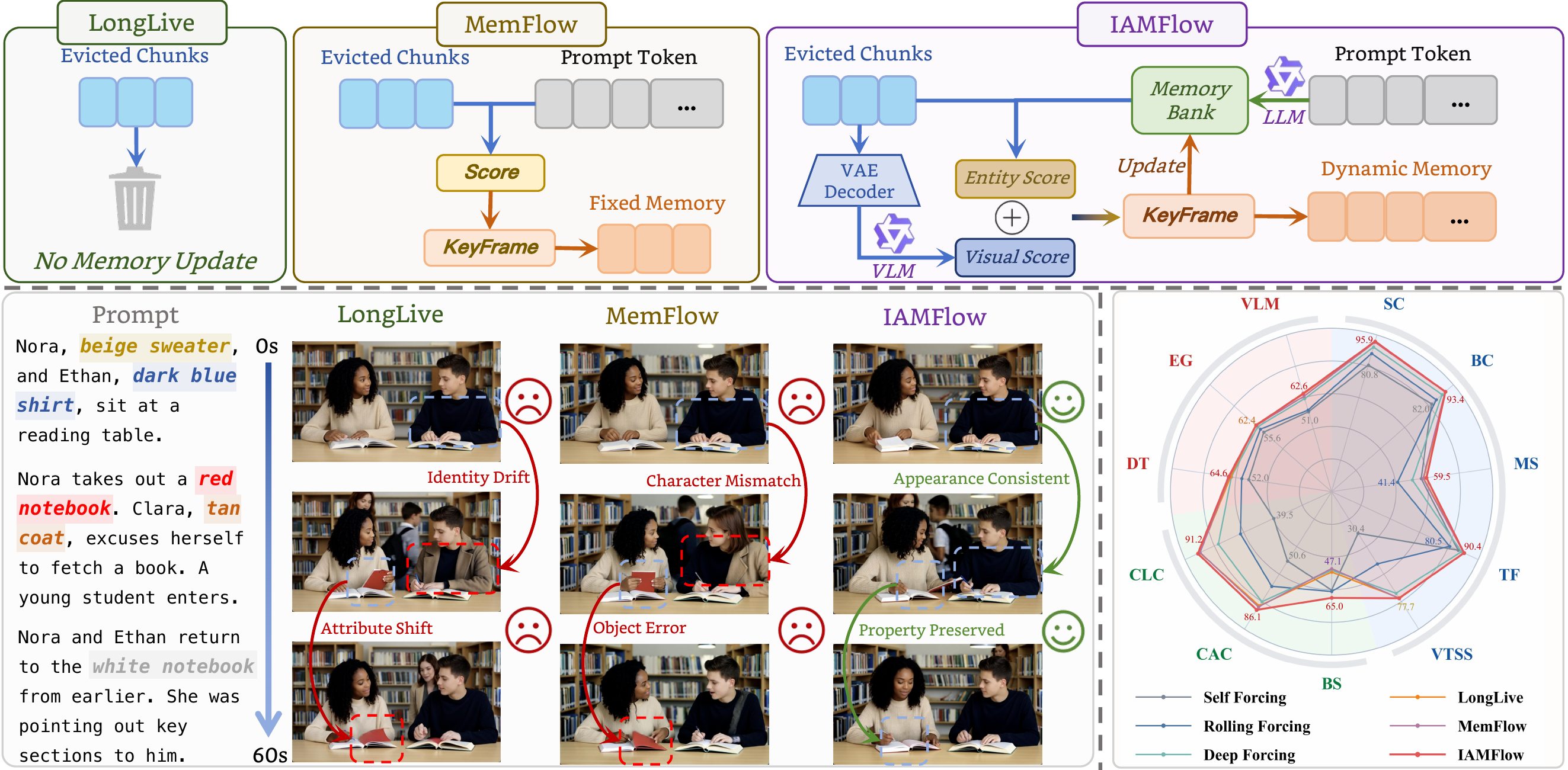
Method: IAMFlow
Framework of IAMFlow
Benchmark: NarraStream-Bench
Overview of NarraStream-Bench
Benchmark Comparison
Comparison of related long-video generation benchmarks. The custom VBench-Long protocol only supports metrics for visual quality.
| Benchmark | VQ | TC | IC | Prompt Type | Aggregation Strategy | Year |
|---|---|---|---|---|---|---|
| VBench-Long | ✓ | × | × | Single | Slow-Fast Avg. | 2024 |
| LV-Bench | ✓ | ✓ | × | Single | VDE | 2025 |
| NarrLV | × | ✓ | ✓ | Single | TNA-based QA | 2025 |
| NarraStream-Bench | ✓ | ✓ | ✓ | Multi | Narrative-Aware | 2026 |
Experiments
Qualitative Visualization

Quantitative Comparison
Quantitative comparison for the multi-prompt 60-second setting on NarraStream-Bench. Self Forcing, Rolling Forcing, and Deep Forcing are adapted for the experiment. Best results are in bold, and second-best results are underlined.
| ID | Method | Visual Quality ↑ | Temporal Consistency ↑ | Instruction Compliance ↑ | Overall ↑ | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SC | BC | TF | MS | VTSS | BS | CAC | CLC | EG | DT | VLM | |||
| 1 | Self Forcing | 80.85 | 82.05 | 86.29 | 56.17 | 30.39 | 60.25 | 50.57 | 39.54 | 55.63 | 51.98 | 50.96 | 56.71 |
| 2 | Rolling Forcing | 88.16 | 85.93 | 80.55 | 41.41 | 52.59 | 61.19 | 68.83 | 62.18 | 58.45 | 56.37 | 52.03 | 63.14 |
| 3 | Deep Forcing | 92.27 | 90.74 | 88.54 | 50.61 | 73.99 | 48.10 | 80.09 | 77.28 | 60.71 | 62.87 | 59.35 | 69.57 |
| 4 | LongLive | 95.36 | 93.32 | 90.27 | 57.76 | 77.29 | 49.19 | 83.06 | 89.97 | 62.40 | 63.33 | 62.22 | 73.17 |
| 5 | MemFlow | 95.37 | 93.21 | 90.23 | 57.37 | 77.67 | 47.06 | 83.92 | 89.71 | 61.93 | 64.14 | 60.85 | 72.88 |
| 6 | IAMFlow | 95.88 | 93.43 | 90.36 | 59.49 | 77.56 | 65.03 | 86.07 | 91.25 | 62.03 | 64.56 | 62.61 | 75.73 |
BibTeX
@misc{liu2026advancingnarrativelongvideo,
title={Advancing Narrative Long Video Generation via Training-Free Identity-Aware Memory},
author={Jinzhuo Liu and Jiangning Zhang and Wencan Jiang and Yabiao Wang and Dingkang Liang and Zhucun Xue and Ran Yi and Yong Liu},
year={2026},
eprint={2605.18733},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2605.18733},
}